Introduction
Multichassis LAG is a tricky concept. In general the members of a bundle (also called LAG, Link Aggregation Group, Etherchannel, Portchannel) are between 2 distinct devices. The advantage of using a bundle is that there is a single routing peering, no worries about spanning tree and things like that. However the redundancy is compromised when either one of the peers fail. Using ECMP (Equal Cost Multipath) in L3 scenarios allows me to dual home to 2 different devices so I have a back up also when one of the peers fail for me, but that negates the benefit of using bundle having a single routing peering.
MC-LAG attempts to provide a means to allow me to dual home a device (DHD, the dual homed device) to two different peer devices (the POA, or Point of Attachment), so basically allowing me to have the benefits of node redundancy, while maintaining single peerings which makes my L2 (Spanning Tree/ STP) or L3 (no dual peerings) life a lot easier.
Does it come with restrictions? Of course! It's technology, nothing comes for free...! So in this document we will highlight how to set it up, what the restrictions are that you need to be aware of and how to troubleshoot and verify MC-LAG scenarios.
Overview
MC-LAG & ICCP enable a switch/router to use standard Ethernet Link Aggregation for device dual-homing, with active/standby redundancy
Dual-homed Device (DHD) operates as if it is connected to single virtual device and runs IEEE std. 802.1AX-2008 (LACP)
Point of Attachment (PoA) nodes run Inter-chassis Communication Protocol (ICCP) to synchronize state & form a Redundancy Group (RG)
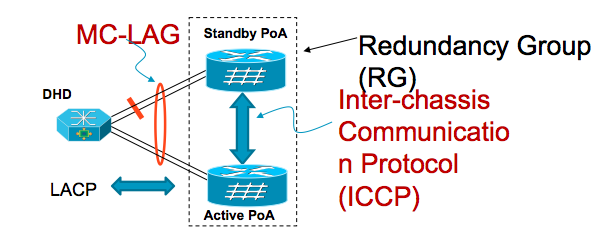
Idea is to let the peer “device” feel that it’s connected to a single “device” •à need information sync between two PoA.
MC-LAG uses ICCP to synchronize LACP configuration & operational state between PoAs, to provide DHD the perception of being connected to a single switch. All PoAs use the same System MAC Address & System Priority when communicating with DHD
Configurable or automatically synchronized via ICCP
1. Port Status
MC-LAG bundle (sub-)interface can be configured for both L2 and L3 service
Service redundancy status may or may not be tied to PoA/bundle active/standby status
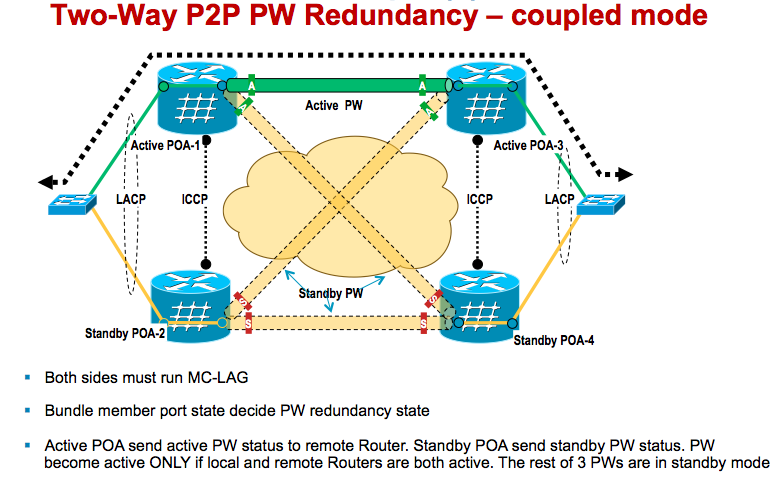
P2P PW (coupled mode): bundle state determine the PW state. If bundle is in active state, then it advertise “active” PW status message.
Otherwise it will advertise “standby” PW status message to its peer Routers
H-VPLS access P2P PW (coupled & one-way mode): PW and its backup PW are in regular “one-way” PW redundancy mode on active POA.
On the standby POA, both of itse PWs are in standby state
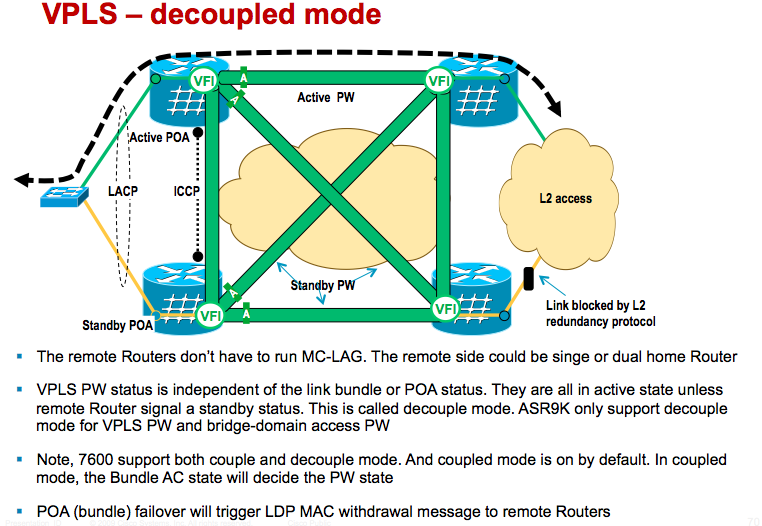
VPLS service (de-coupled mode): regardless if bundle is active or standby, VPLS PWs are always in active forwarding state
H-VPLS access PW (PW under bridge-domain): same de-coupled mode as VPLS
L3 service (coupled mode): bundle state determine the L3 sub-interface state.
If bundle is in active state, then bundle L3 interface/sub-interface keep up. Otherwise, it keeps in protocol “down” state
Configuration
The following configuration is recommended for mLACP operation.
2. ICCP setup (POAs)
First, an ICCP group must be set up. This configuration is not owned by the bundle infra, so only a simple example setup is provided here. For more details please refer to the information provided by the ICCP team.
On each POA, the following is required:
- An IPv4 address at each end of the link between the POAs to provide IP connectivity.
- An IP address set up on a loopback interface as the endpoint for the LDP link over which ICCP operates;
- A routing protocol so that the routes can be determined (static route in the example, for which proxy-arp on the connection between POAs is required);
- An LDP session to connect to the peer.
RP/0/0/CPU0:ios(config)#interface <link connected to peer POA> RP/0/0/CPU0:ios(config-if)#ipv4 address <IP address; e.g. 4.0.0.[1-2]/8> RP/0/0/CPU0:ios(config-if)#proxy-arp RP/0/0/CPU0:ios(config-if)#root RP/0/0/CPU0:ios(config)#interface Loopback <ID> ipv4 address <IP address; e.g. 5.4.3.[1-2]/32> RP/0/0/CPU0:ios(config)#router static address-family ipv4 unicast <IP of peer POA, e.g. 5.4.3.[2-1]/32> <IP of far end of link between POAs, e.g. 4.0.0.[2-1]> RP/0/0/CPU0:ios(config)#mpls ldp RP/0/0/CPU0:ios(config-ldp)#router-id <unique ID, e.g. 5.4.3.<1-2>> RP/0/0/CPU0:ios(config-ldp)#discovery targeted-hello accept RP/0/0/CPU0:ios(config-ldp)#log neighbor RP/0/0/CPU0:ios(config-ldp)#interface <link connected to other POA> RP/0/0/CPU0:ios(config-ldp)#commit
The next step is to add an ICCP redundancy group on each POA; using the same group ID for both:
RP/0/0/CPU0:poa1(config)#redundancy iccp group <group-id> member neighbor <LDP router-id of other POA> RP/0/0/CPU0:poa1(config)#commit
NB: The same ICCP group ID must be used on both POAs.
At this point the two POAs should connect and start running ICCP. However, it may take a little while for the ICCP connection to be established. Once connected, the peer POA's information should appear in the show iccp group <group-id> command, and its state should be up (connected). NB: The configuration and commands up to this point are not owned by the bundle infra; please refer to the information from the ICCP team for more details. (However, if you investigate and find these instructions incorrect or out of date, please let us know!)
3. mLACP setup (POAs)
The underlying ICCP session has now been established. To enable the mLACP session, some further configuration settings are required under the ICCP group:
- The system MAC, which should be the same on both POAs;
- The system priority, which should be the same on both POAs, and a priority of 1 is recommended;
- The node ID, which must be different on each POA.
RP/0/0/CPU0:ios(config)#redundancy iccp group <ICCP group ID> RP/0/0/CPU0:ios(config-redundancy-iccp-group)#mlacp system mac <ID unique to group, same on both POAs> RP/0/0/CPU0:ios(config-redundancy-iccp-group)#mlacp system priority 1 RP/0/0/CPU0:ios(config-redundancy-iccp-group)#mlacp node <ID unique to each device in the group> RP/0/0/CPU0:ios(config-redundancy-iccp-group)#commit
Next, a bundle needs to be added to the ICCP group, with a configured MAC address. In order to protect against flaps during switchover operations, please add the recommended configuration items below. Matching configuration is required on both POAs. This includes using the same number for the bundle interface, and the same MAC address.
RP/0/0/CPU0:ios(config)#interface Bundle-Ether <x> RP/0/0/CPU0:ios(config-if)#mac-address 0001.0002.0003 RP/0/0/CPU0:ios(config-if)#bundle wait-while 100 RP/0/0/CPU0:ios(config-if)#lacp switchover suppress-flaps 300 RP/0/0/CPU0:ios(config-if)#mlacp iccp-group <ICCP group ID> RP/0/0/CPU0:ios(config-if)#commit
On the POAs, the last step is to add members to the bundle, as you would with normal LACP. The period configuration is optional; it enables faster LACP timeouts.
RP/0/0/CPU0:ios(config)#interface <Ethernet interface> RP/0/0/CPU0:ios(config-if)#bundle id <x> mode active RP/0/0/CPU0:ios(config-if)#lacp period short
4. DHD setup
All that's left is to add the bundle and member configuration on the DHD. If the DHD is an XR box running the new software, the configuration is as follows:
RP/0/0/CPU0:ios(config)#interface Bundle-Ether <y> RP/0/0/CPU0:ios(config-if)#bundle wait-while 100 RP/0/0/CPU0:ios(config-if)#lacp switchover suppress-flaps 300 RP/0/0/CPU0:ios(config-if)#root RP/0/0/CPU0:ios(config)#interface <each interface connected to POAs> RP/0/0/CPU0:ios(config-if)#bundle id <y> mode active RP/0/0/CPU0:ios(config-if)#lacp period short RP/0/0/CPU0:ios(config-if)#commit
Any non-XR device (or XR up to R3.9) should have a bundle and members configured similarly. NB: Against some implementations the expected behavior is that the bundle will flap on a switchback event for up to 2 seconds. To avoid this, lacp fast-switchover (IOS) or equivalent configuration is required.
If lacp fast-switchover or similar configuration is not available on the DHD, lacp switchover suppress-flaps 2500 configuration can be added on the bundle on the POAs to avoid the state flap. However, this will result in ~2 seconds of traffic loss on the switchback event (though the bundle stays up).
If the lacp switchover suppress-flaps configuration or some kind of state dampening is not used or not available on the DHD, a bundle flap on the DHD on a switchover or switchback event is expected.
5. Checking status
The members added to the bundle on one POA will go Active, and the members on the other POA will be in Standby state. This can be verified using show bundle on either POA to display the membership information for correctly configured members on both the POAs:
RP/0/0/CPU0:ios#show bundle Mon Jun 7 06:02:46.507 PDT Bundle-Ether1 Status: Up Local links <active/standby/configured>: 1 / 0 / 1 Local bandwidth <effective/available>: 1000000 (1000000) kbps MAC address (source): 0000.deaf.0000 (Configured) Minimum active links / bandwidth: 1 / 1 kbps Maximum active links: 64 Wait while timer: 100 ms Load balancing: Default LACP: Operational Flap suppression timer: 300 ms Cisco extensions: Disabled mLACP: Operational ICCP Group: 1 Role: Active Foreign links <active/configured>: 0 / 1 Switchover type: Non-revertive Recovery delay: 300 s Maximize threshold: Not configured IPv4 BFD: Not configured Port Device State Port ID B/W, kbps -------------------- --------------- ----------- -------------- ---------- Gi0/0/0/0 Local Active 0x8001, 0x9001 1000000 Link is Active Gi0/0/0/0 5.4.3.2 Standby 0x8002, 0xa001 1000000 Link is marked as Standby by mLACP peer RP/0/0/CPU0:ios#
Switchover
To switch which POA is active you can use the following CLI command on the currently active router:
mlacp switchover Bundle-Ether 1
The following example illustrates a switchover using this command.
RP/0/0/CPU0:ios#show bundle Mon Jun 7 06:02:46.507 PDT Bundle-Ether1 Status: Up Local links <active/standby/configured>: 1 / 0 / 1 Local bandwidth <effective/available>: 1000000 (1000000) kbps MAC address (source): 0000.deaf.0000 (Configured) Minimum active links / bandwidth: 1 / 1 kbps Maximum active links: 64 Wait while timer: 100 ms Load balancing: Default LACP: Operational Flap suppression timer: 300 ms Cisco extensions: Disabled mLACP: Operational ICCP Group: 1 Role: Active Foreign links <active/configured>: 0 / 1 Switchover type: Non-revertive Recovery delay: 300 s Maximize threshold: Not configured IPv4 BFD: Not configured Port Device State Port ID B/W, kbps -------------------- --------------- ----------- -------------- ---------- Gi0/0/0/0 Local Active 0x8001, 0x9001 1000000 Link is Active Gi0/0/0/0 5.4.3.2 Standby 0x8002, 0xa001 1000000 Link is marked as Standby by mLACP peer RP/0/0/CPU0:ios#mlacp switchover Bundle-Ether 1 Sun Jan 31 23:46:43.706 PST This will trigger the peer device (0/0/CPU0 (0x0)) to become active for Bundle-Ether1. This may result in packet loss on the specified bundle. Proceed with switch over? [confirm] RP/0/0/CPU0:Jan 31 23:46:44.666 : BM-DISTRIB[282]: %L2-BM-5-MLACP_BUNDLE_ACTIVE : This device is no longer the active device for Bundle-Ether1 RP/0/0/CPU0:Jan 31 23:46:44.668 : BM-DISTRIB[282]: %L2-BM-6-ACTIVE : Gi0/0/0/0 (0x20000020) is no longer Active as part of Bundle-Ether1 (Not enough links available to meet minimum-active threshold) RP/0/0/CPU0:ios#show bundle Mon Jun 7 06:04:17.778 PDT Bundle-Ether1 Status: mLACP hot standby Local links <active/standby/configured>: 0 / 1 / 1 Local bandwidth <effective/available>: 0 (0) kbps MAC address (source): 0000.deaf.0000 (Configured) Minimum active links / bandwidth: 1 / 1 kbps Maximum active links: 64 Wait while timer: 100 ms Load balancing: Default LACP: Operational Flap suppression timer: 300 ms Cisco extensions: Disabled mLACP: Operational ICCP Group: 1 Role: Standby Foreign links <active/configured>: 1 / 1 Switchover type: Non-revertive Recovery delay: 300 s Maximize threshold: Not configured IPv4 BFD: Not configured Port Device State Port ID B/W, kbps -------------------- --------------- ----------- -------------- ---------- Gi0/0/0/0 Local Standby 0x8003, 0x9001 1000000 mLACP peer is active Gi0/0/0/0 5.4.3.2 Active 0x8002, 0xa001 1000000 Link is Active RP/0/0/CPU0:ios#
This command should cover most of the required information. However, for a more detailed look, there is also an mLACP-specific command available. This gives you information about each router in each redundancy group, and the state and configuration each has advertized for each bundle.
RP/0/0/CPU0:ios#show mlacp Mon Jun 7 06:05:36.901 PDT ICCP Group 1 Connect timer: Off Node LDP ID State System ID Sync Vers ---- --------------- ------------ ------------------------ ----- ---- 1 Local Up 0x0001,00-0d-00-0e-00-0f Done - 2 5.4.3.2 Up 0x0001,00-0d-00-0e-00-0f Done 1 Bundle-Ether1 (ROID: 0000.0001.0000.0000) Node Aggregator Name State Agg ID MAC Address ---- -------------------- ---------- ------ --------------- 1 Bundle-Ether1 Up 0x0001 0000.deaf.0000 2 BE1 Up 0x0001 0000.deaf.0000 RP/0/0/CPU0:ios#
Troubleshooting
In this section some basic verification tips that can be checked out that hopefully pinpoint to the culprit when MC-LAG is not working as we expected.
6. Information to Collect
Please collect the following information to be provided in any triage request for mLACP issues. Before submiting a TAC case please follow the steps set out in the following sections to diagnose some more common faults and misconfigurations:
- Details of the symptoms, and which POA is experiencing them (with timestamps if possible).
- The sequence of events that triggered the issue. [mLACP states can be history-dependent so it can be important to know the previous bundle configuration.]
The following logs from both of the POAs:
show tech bundle
show tech bundle in admin mode.
show iccp group
show iccp counters
show iccp trace
- The following logs from the DHD:
show tech bundle
show tech bundle in admin mode.
7. Is this a bundle issue?
Checking ICCP
If you are seeing unexpected mLACP behavior, the first thing to check the health of the ICCP layer (which mLACP relies on) to ensure it is in the expected state. Normally ICCP should be up with a group member present (unless you are testing split brain or device-level failure):
RP/0/0/CPU0:ios#show iccp group Wed Feb 10 22:58:58.845 PST Redundancy Group 1 member ip:5.4.3.2 (ios), up (connected) monitor: route-watch (up) No backbone interfaces. enabled applications: mLACP RP/0/0/CPU0:ios#
If you have a backbone interface configured, it should normally be showing as up unless core isolation is in effect:
RP/0/0/CPU0:ios#show iccp group Wed Feb 10 23:04:03.406 PST Redundancy Group 1 member ip:5.4.3.2 (ios), up (connected) monitor: route-watch (up) backbone interface Gi0/0/0/3: up enabled applications: mLACP RP/0/0/CPU0:ios#
If the output of this command is not what you are expect, the issue needs to be dealt with by the ICCP team. Please refer to information from the ICCP team, or contact them if you believe there is a problem.
Features & Protocols
If there is a problem with features that run on the bundle but the bundle IM state/LACP state is correct, then the team for the particular feature should be contacted. As with normal bundle interfaces, the Bundle Infra controls the bundle interface itself, and other components are responsible for running their services over the bundle.
This info will help you direct the TAC where to send the case to. Is it really an MC-LAG issue, or a feature issue (that might exist on a regular bundle also) or is there just an issue with teh bundle itself. These items are handled by different development groups, so it helps to drill down the failure issue to a most common set of problems that will inherently mean a faster case resolution as the sw problem can be dealt with immediatley with the right group.
8. Bundle Infra issues
The bundle is down
To identify the issue, please go through the following steps:
- Check whether ICCP is healthy, as described above. If not, this is likely to be the cause of the issue. Please correct this and see if the problem persists.
Verify that the configuration is correct for the ICCP group and the bundles. Correct any misconfigurations and see if the issue persists.
Check that the minimum-active links/bandwidth configuration is set to an appropriate value (i.e. smaller than the number of links in the bundle/their total bandwidth).
The output of the show bundle command should tell you the reason any member links are not Active. The output of this command (combined with the table of reasons with additional information should indicate the cause of the problem and how to fix it.
- If you are still seeing that the bundle is down, please collect the information listed above.
9. The bundle flapped on the POA
Bundle flaps are sometimes expected on mLACP events, but they are usually the result of misconfigurations. So the first thing to do is check that all your configuration is correct. Please refer to the configuration guidance for details, and specifically take note of the following:
- If a protocol flap is seen (e.g. OSPF) but not a flap in the state of the bundle interface itself, please refer to the feature-specific wiki and follow up with the team responsible for the feature.
The mlacp system priority and mlacp system mac configured under redundancy iccp group <x> must be configured to be the same value on both devices in the RG.
The same mac-address should be configured on the bundle interface on both POAs.
If the DHD supports bundle wait-while 100 (XR 4.0) or lacp fast-switchover (XR up to 3.9 & IOS) or equivalent, this should be configured on the DHD.
If the DHD has bundle wait-while 100 configuration, lacp switchover suppress-flaps 300 should be configured on the POAs. Otherwise, lacp switchover suppress-flaps 2500 is required.
The bundle should be configured with bundle wait-while 100 on the POAs.
- Check for any syslogs or bistate alarms that could indicate the cause of the flap.
If you're still seeing a flap, please collect the information requested above.
10. The bundle flapped on the DHD
Bundle flaps on the DHD are usually expected during switchover events. If an XR 4.0 device is in use, you can configure bundle wait-while 100 and lacp switchover suppress-flaps 300 on the bundle to avoid a flap (assuming the POAs are set up correctly as above). If other DHD software provides similar functionality it can be used, otherwise a flap cannot be avoided.
11. Switchover did not occur
This is likely to mean one of the following:
The bundle is Down on the Standby POA (and was Down before the switchover attempt). The output of show bundle on the Standby POA should indicate the reason for this.
- The two POAs are not communicating over ICCP. See the "Checking ICCP" section above for details.
12. Both POAs are Active
This should only happen when the POAs are failing to communicate over ICCP. See the "Checking ICCP" section above for details.
13. The bundle is Down on the Active POA
This can happen if:
- There is no Standby POA to switch over to, or the bundle is Down on the Standby POA.
- The required number of links have been put in LACP Selected state, but have not been Activated (e.g. due to failing to progress further in LACP negotiations). A switchover cannot be performed in this scenario. This could indicate a misconfiguration on the DHD.
14. The bundle is Up on the Standby POA
This is expected. Please see the section on Interface State in the events and scenarios section.
Events and Scenarios
15. Initial Bringup
By default, when the first device is added to the ICCP group, it does not enable any bundles in that ICCP group until negotiations with a peer have been completed. This is to reduce churn when adding a device to the group (or reloading the device).
This means that without an mLACP peer, mLACP bundles cannot be enabled. It could also lead to the following:
- Two routers (A and B ) are configured as mLACP peers and start operating their mLACP bundles.
- Router B crashes. Router A takes over operation of all bundles and continues running on its own.
- Router A is reloaded. After it comes up it waits indefinitely for the peer, and therefore does not bring up any of the mLACP bundles.
If this is undesirable, the following configuration can be used:
RP/0/0/CPU0:ios(config)#redundancy iccp group 1 mlacp connect timeout ? <0-65534> Number of seconds to wait before assuming mLACP peer is down. RP/0/0/CPU0:ios(config)#
If a connect timeout is configured and no peer device is present, mLACP bundles will be enabled once the timeout has elapsed after joining the ICCP group.
16. mLACP Active and Standby
Each of the mLACP peer devices is either the Active or the Standby device for each bundle. On each device, its status (Active or Standby) is displayed in the mLACP section of the show bundle output.
Interface State
The bundle interface state (as displayed in show interfaces) can be Up or Down on either the Active or the Standby device for the bundle. On both devices, under normal conditions, the bundle should be Up.
The bundle interface state will be Down on the Active device if:
- The minimum link threshold could not be met (or no links could be brought up) and there is no mLACP peer advertising that it is ready to bring the bundle Up (so a switchover cannot be performed).
- The required number of links have been put in LACP Selected state, but have not been Activated (e.g. due to failing to progress further in LACP negotiations). Again, a switchover cannot be performed in this case. This could indicate a misconfiguration on the DHD.
The bundle interface will be Down on the Standby device if:
- The device is not ready to forward bundle traffic; if the bundle goes down on the Active device, traffic will be lost.
- The device is cold standby for the bundle (see next subsection).
Hot vs Cold Standby
In the show bundle output, the state of the bundle on the standby POA could be either of the following:
mLACP Hot Standby: This bundle has enough links available, it is Up in IM, and it has the required POA configs to take over without a flap if the active router goes down. NB: This does not guarantee that the bundle will take over without a flap. Incorrect/incompatible configuration on the DHD could still lead to a flap.
mLACP Cold Standby: The bundle has enough links available to take over if required. However, it is marked as Down in IM because it will have to be Down initially after the switchover while LACP negotiations are in progress. This is due to some missing configuration that is required for a seamless switchover; e.g. lacp switchover suppress-flaps.
Please see the
17. Switchover
The following subsections provide more details on mLACP switchover and switchback events and the behavior under various conditions.
Switchover Types
The mLACP switchover method can be modified using the following CLI:
RP/0/0/CPU0:ios(config)#interface bundle-ether 1 mlacp switchover type ? brute-force Force switchover by disabling all local member links revertive Revert based on configured priority values RP/0/0/CPU0:ios(config)#interface bundle-ether 1 mlacp switchover type
These options (and the default, when this configuration is not present) are mutually exclusive, and the value must match on the bundle on both POAs. They determine whether the dynamic priority management or brute force mechanism is used, and whether the behavior is revertive or non-revertive.
The behavior can also be modified to maximize the links or bandwidth available using one of the following CLIs:
interface <bundle> mlacp switchover maximize bandwidth [threshold <kbps>] interface <bundle> mlacp switchover maximize links [threshold <count>]
This causes the active device to be the one with more bandwidth or more links available in the bundle. If a threshold is specified, this behavior only takes effect once the available links/bandwidth on one device falls below the threshold. This must be configured symmetrically on both devices.
Dynamic Priority Management
Dynamic priority management means that a switchover is achieved gracefully by modifying the LACP port priorities.
- Before any switchovers have occurred, the LACP port priorities for the members on each POA match the value configured using the mlacp port-priority configuration for the bundle interface, or 32768 as a default if there is no value configured.
- To perform a switchover, the priorities at which the links are operating on at least one POA are changed automatically by the POA software so that the links to the POA which is to go active are higher-priority (have a smaller LACP priority number) than the links attached to the other POA. (This means the configured value can differ from the operational value.)
- LACP demands the highest-priority links must be selected ahead of lower-priority ones (by the DHD as well as the POAs), which is why this action triggers a switchover.
- In almost all cases, the port priority of the currently-active POA is reduced (the operational priority number is increased) to trigger a switchover to the peer POA. This avoids churn in the LACP state machines on the links to the POA becoming active.
- If this is not possible (i.e. if the operating priority of the standby POA is 65535 so there are no larger numbers available) the priorities of both are modified; the newly active POA's links take priority 1 and the other POA's take priority 2.
It is possible to reset the priorities used on both POAs to their initial values. Doing so will cause a switchover if the device with the higher configured port priority is in the standby role at the time the command is issued.
RP/0/0/CPU0:ios#mlacp reset priority Bundle-ether 1 Sun Aug 28 16:12:58.110 BST Warning: this will reset all negotiated mLACP sessions on Bundle-Ether1. If traffic is flowing over this bundle, traffic loss WILL occur. Proceed with priority reset? [confirm] RP/0/0/CPU0:Aug 28 16:13:02.983 : BM-DISTRIB[1132]: %L2-BM-6-MLACP_BUNDLE_ACTIVE : This device is now the active device for Bundle-Ether1
Brute Force
The brute force mechanism does not involve any priority changes. When using brute force, the operational priority always matches the configured priority. A switchover is performed as follows:
- When the bundle goes down on the active POA (e.g. the minimum-active links threshold is breached), the LACP state machine is updated for any ports that are not encountering problems on the active POA. (Any ports which have lost connectivity to trigger the condition should already have been deselected.)
- These updates to the LACP states are transmitted over mLACP to the other POA.
- A final LACP packet is sent to the DHD on each of the links to the Active POA to cause the DHD to deselect them as well (and select links to the other POA in preference).
- After this, there is no further LACP transmission on those links. This means that the state of these links is not being monitored by LACP.
- To recover from this situation, once the link that failed has recovered (enough to be LACP Selected) LACP operations are restarted on the remaining links.
Revertive Behavior
Revertive behavior means that the bundle effectively has a "primary" and a "secondary" POA. The bundle is active on the primary POA whenever possible. It is only active on the secondary POA when it is down on the primary, or the secondary has more available links and the maximize threshold has been breached.
The calculation to determine which POA is the "primary" for the bundle is as follows.
- If the POAs have different mlacp port-priority configuration for the bundle, the one with the higher priority configured (smaller number) is the primary.
- If the configured bundle mLACP priorities match, the POA with the smaller mlacp node configuration in the redundancy group is the primary.
- NB: Between two POAs in an RG sharing multiple bundles, it's possible for each POA to be a primary for some of the bundles.
Bu default, when the primary POA recovers, it delays going active for 300 seconds to allow higher-layer ICCP-aware protocols (e.g. routing protocols) to sync their state between devices. This helps avoid churn and downtime at higher layers. The delay time can be modified using the following configuration setting:
interface <bundle> mlacp switchover recovery-delay <time in seconds>
Non-revertive Behavior
Non-revertive behavior does not consider POAs to be "primary" and "secondary"; only "active" or "standby". The configured priorities are only used to determine which POA is initially active. After this point, the active POA remains active until it encounters a failure, or mlacp maximize settings are in effect and the peer router has more links or bandwidth available (see later for details).
So without mlacp maximize there is no "switchback" in this mode; when a POA recovers from a failure, it remains standby until the other POA fails.
This mode of operation causes least churn, and is the recommended option.
Notes
The configuration options map to the following:
- Default: Dynamic priority management with non-revertive behavior.
- brute-force: Brute force mechanism with revertive behavior.
- revertive: Dynamic priority management with revertive behavior.
Two things to note about the available settings:
- Brute force operation is not compatible with non-revertive operation; it is inherently revertive because the POA with the higher operational priority is fixed by configuration. So a combination of these options is not available.
- If the DHD is the higher priority LACP system the LACP port priorities set by the POAs for the members are ignored. So the only mechanism that can be used is brute force, regardless of the configuration. An alarm is raised by the Bundle Infra on the bundle to indicate when this happens.
18. Switchover Triggers
The following events can trigger a switchover to the mLACP peer:
- Link failure: A port or link between the DHD and one of the POAs fails.
- Device failure: Meltdown or reload of one of the POAs, with total loss of connectivity (to the DHD, the core and the other POA).
Core isolation: A POA loses its connectivity to the core network and therefore is of no value, being unable to forward traffic to or from the DHD.
NB: Other documents (e.g. from IOS) may discuss 5 failure cases, listed as A-E. These map onto the above as follows:
- Failure of upstream port on the DHD: Covered by link failure case.
- Failure of link between DHD and POA: Covered by link failure case.
- Failure of downstream port on the POA: Again considered a type of link failure in the above set.
- Node failure: Described here as device failure, to clarify that it describes the router failing.
- PE isolation: Named core isolation here.
The following sections give more detail on each type of failure, how they can be produced, and the expected results. Each of these events only result in a switchover if the bundle is in (hot or cold) standby state on the standby POA; otherwise the bundle will be Down on both routers.
Link Failure
This can be triggered for testing purposes by disabling an active bundle member when:
- The bundle on standby POA is listed in an mLACP Standby state in show bundle.
- There are no Standby links connected to the currently active POA.
- Either of the following is the case:
- Once the link is removed, there is not enough bandwidth/links in the bundle on that POA to meet a configured minimum-active threshold.
- Once the link is removed, the amount of links/bandwidth in the bundle is below the mlacp maximize threshold and the standby POA has more links/bandwidth available in the bundle than the active POA.
The member can be removed from the bundle using any of the following events:
- Fiber pull at either end of the POA-DHD link. (NB: This is the most representative way of testing this scenario.)
- Shut down the POA-DHD link on the DHD.
- Shut down the POA-DHD link on the POA.
- Remove the bundle membership configuration on either end of the POA-DHD link.
Device Failure
This represents a meltdown of the router carrying the traffic; total loss of the node. The only valid test trigger for this event is a hard reset (power down) of the device, even a router reload is not truly representative as the device will tend to go down in a series of indeterminate stages.
Core Isolation
This is an ICCP event meaning that connectivity to the network core has been lost. The configuration for core connectivity monitoring is owned by ICCP and not the Bundle Infra, so the following is only a brief description of the basic steps required; please see ICCP documentation for more details.
One or more "backbone interfaces" can be configured under the redundancy group for monitoring by ICCP:
RP/0/0/CPU0:ios(config)#redundancy iccp-group <id> RP/0/0/CPU0:ios(config-redundancy-iccp-group)# backbone interface <core-facing interface name>
A core isolation event will be declared by ICCP when all the specified interfaces are operationally down, or not present (e.g. node reload). (If the interfaces do not exist or are down when they are configured, core isolation is declared immediately. In all cases it can be cleared by removing the backbone interface configuration.)
If a POA experiences this event it sends dying gasp LACP packet to the DHD on its member links and stops LACP negotiations on them, using the same mechanism as if a brute force switchover was being performed. However, it also changes port priorities on all links if dynamic priority management is in effect (in accordance with the revertive or non-revertive behavior described above) as appropriate.
19. User-Controlled Switchover
There are a couple of configuration commands that can be used to bring a bundle down on one POA, triggering a switchover to its mLACP peer. Additionally, in some cases exec CLI commands can be used to control the switchovers.
Bundle Interface Shutdown
The first is simply:
RP/0/0/CPU0:ios(config)# interface Bundle-Ether <x> RP/0/0/CPU0:ios(config-if)# shutdown
This brings down all the links in the bundle interface and forces a switchover to the peer. This can be used in all cases to force a switchover. However, this means that neither the LACP states nor even the link states of the bundle members can be monitored while the bundle is down.
This works for all switchover modes.
Bundle Interface Bundle-level Shutdown
If a dynamic priority management form of switchover is in use, i.e. the bundle is not configured to use brute force switchover and the POAs are the higher priority LACP system, there is an alternative command:
RP/0/0/CPU0:ios(config)# interface Bundle-Ether <x> RP/0/0/CPU0:ios(config-if)# bundle shutdown
With this slight variation, instead of bringing the member links down, they are kept in LACP Standby state. The bundle is declared down so the mLACP peer takes over. However, LACP continues to operate and the health of the links can be verified before allowing them to come up again.
This works for revertive and non-revertive switchover modes (not brute force). NB: The DHD also has to be the lower priority LACP system, otherwise brute force will implicitly be used.
Non-revertive Switchover CLI
CLI commands are also available for performing a switchover on user demand. To use these commands, the bundle must be using the default mLACP switchover behavior (non-revertive). (Otherwise the bundle would have to simply revert to the originally active router immediately.)
A switchover to the standby POA can be performed by issuing the following command on the active POA:
RP/0/0/CPU0:ios# mlacp switchover Bundle-Ether <x>
If required, the same operation can be performed on the standby POA to become active:
RP/0/0/CPU0:ios# mlacp switchback Bundle-Ether <x>
However, the switchback command could cause a bundle flap on the POA that is becoming active, so it is preferable to use the switchover command on the other POA if possible.
These commands can also be set with a delay, for the switchover to be performed at some point in the future. Some examples:
RP/0/0/CPU0:ios# mlacp switchover Bundle-Ether <x> in 5 minutes RP/0/0/CPU0:ios# mlacp switchback Bundle-Ether <x> in 3 hours RP/0/0/CPU0:ios# mlacp switchover Bundle-Ether <x> at 08:45:30
If it is necessary to cancel a scheduled switchover or switchback operation the following commands can be used. The switchover and switchback variants can be used per bundle, the scheduling variant affects all scheduled bundle actions.
RP/0/0/CPU0:ios# clear mlacp switchover Bundle-Ether <x> RP/0/0/CPU0:ios# clear mlacp switchback Bundle-Ether <x> RP/0/0/CPU0:ios# clear mlacp scheduling
mLACP Synchonization
Synchronization between mLACP peer devices occurs on a number of occassions.
- When connecting to a peer device mLACP will send a full (unsolicited) sync of all its configuration and state for the relevant ICCP group. It will also request a full sync from the peer device.
- When inconsistent or incompatible data relating to a foreign port or a mutual object (i.e. a bundle or system setting) is received from a peer a full resync is requested. The exception to this is the case where the data is received as part of a resync in which case it is NAKd. See the following section for more details.
- When incorrect data relating to a local port is received from a peer a full resync of the local configuration and state is sent back to the peer.
- When the local node id is changed a full resync of local configuration and state is sent to the peer device. This is done because the node id forms part of the identifier for every port so it is necessary to purge the old port data and replace it with the new.
The XR implementation of mLACP always requests a full resync although the protocol allows for resyncs to be requested for particular objects. This is done for reliability reasons as well as practicalities of implementation. Similarly when a resync is request is received, or when sending an unsolicited sync, the XR implementation always responds with a full resync of local configuration and state regardless of what was requested. This is fully compatible with the behavior outlined in the standard.
NAKing mLACP Messages
Messages can be NAKd for a number of reasons, including but not limited to
- Invalid TLV contents (e.g. value out of range)
- Incompatibility between local and peer device (e.g. clashing node id or different bundle ROID on each device)
- Object or parent object referenced in the message is not found in the local database
As explained above, typically when a message is received for which there is some sort of issue a resync is first requested (or sent). If an issue is detected within an incoming sync, or for problems such as an incorrect ROID for a bundle which cannot be resolved with a resync, then a message is NAKd.
When a message is NAKd the object referred to the in the message is disabled in some way. The behavior depends on the type of object.
- If a NAK for a local port, bundle or system is received it is disabled for LACP operation
- If a NAK for a remote port, bundle or system is sent it is removed from the local database
- If a NAK for a remote bundle or system is sent the corresponding local object is disabled for LACP operation
All operations cascade to child objects.
To re-enable an object after it has been NAKd there must be some change in its configured state that causes a new Config TLV to be sent. This resets the NAKd state, although it is possible that the new Config TLV will be immediately NAKd again if the change is not acceptable either.
20. Configuration Changes
Certain elements of mLACP configuration are key, and mismatches or even configuration changes can have an impact on mLACP operation.
mLACP Node ID
The value configured for the mlacp node under the ICCP group submode is used in the LACP parameters for bundles in that ICCP group. This value must be present for bundles in the ICCP group to be operational, and must differ on each device in the ICCP group.
When this value is modified, the LACP session must be renegotiated on each link of each bundle in the ICCP group. This causes the interface state of all the bundles to flap.
mLACP System ID
The mlacp system priority and mlacp system mac values under the ICCP group are also required for bundles in the ICCP group to be operational. These values must be the same on each router in the ICCP group.
Once again, these values are used in LACP negotiations, so changing them causes all the bundles to flap. (This is why they must be the same on all devices: Otherwise, when the Active device fails, all the LACP sessions on the Standby have to be renegotiated using its system ID.)
21. Split Brain
If the ICCP link between the POAs goes down but both POAs remain up, a "split brain" situation is said to have occurred, meaning that the POAs cannot exchange state information and are not aware of each other's presence.
In this scenario, both POAs would attempt to go active: From each one's perspective, it appears the other has encountered a device-level failure. This can be protected against in a limited manner in some cases, using DHD control as described below.
22. DHD Control
In the recommended configuration, the switchovers are controlled only by the POAs. The DHD is always trying to make all links active, and the required set are kept in standby by the POA.
However, if the DHD supports maximum-active links configuration, this can be used to protect against both POAs going active in a split brain scenario if all of the following conditions are met:
- The DHD has the same number of links to each POA in the bundle.
- The POAs are configured with minimum-active links <number of links to the DHD>.
- The DHD is configured with maximum-active links <number of links to each POA>.
Additionally, if either POA has brought down its links by brute-force (i.e. due to brute-force behavior being in effect), forwarding on the bundle could stop (i.e. the bundle could go down on both POAs) when the split brain event occurs. Therefore dynamic priority management is recommended.
If a split brain event occurs with this configuration present, the POAs will continue to operate with the same priorities as they had before and will both try to go active. However, the DHD will only allow the links to the POA with higher link priorities to go active due to the maximum-active links configuration.
NB: A switchover cannot be coordinated between the POAs while split brain is in effect. So if the active POA encounters a failure, there is no guarantee that bundle will switch over to the other POA. (The exact behavior depends on the number of bundle member links and the manner of the failure.)
Syslog messages
The following lists all the possible syslog messages from the bundle infra specific to mLACP, along with their meanings. In addition many of the RED_MGMT messages relate to LACP and mLACP and may be relevant. Refer to the documentation for that message in the regular troubleshooting guide.
MLACP_CANNOT_SWITCHOVER: Could not perform mLACP switchover/switchback requested by user for bundle <name>: <reason>
A switchover request was triggered using the mlacp switchover <bundle> CLI, and the Bundle Infra has attempted to perform the switchover. However, the bundle was not in an appropriate state to switch over, so no action was taken. This could be because:
- One of the mLACP peers is down.
- The bundle is not active on the node being switched from.
- The switchover behavior in operation is not non-revertive.
MLACP_CONNECT_FAILED: Failed to connect to another mLACP device in ICCP Group <id>. Reason: <reason>
The connection failed so mLACP will not operate over the specified ICCP group. Most likely this is be because no peer device is configured to run mLACP in this group. Other possibilities include
Version mismatch between the two devices. The output of show mlacp can be used to check the version the device is using.
There are more ICCP connections than can be supported currently set up; this can be checked in configuration and corrected if required. To retry the connection, remove and re-add the mlacp node configuration under the ICCP group.
MLACP_CONNECT: Connected to <LDP ID>
A connection to the specified mLACP peer device has been established.
MLACP_DISCONNECT: Disconnected from <LDP ID>
The connection to the peer device identified has been terminated.
MLACP_SYSTEM_ID_ARBITRATION: The system ID for ICCP group <id> has been established by arbitration
If the system ID was established by arbitration then there is a misconfiguration or unadvisable choice of configuration; a different mlacp system priority or mlacp system mac has been specified for the same ICCP group by different peers. One of the values is chosen for operational purposes, but if the peer who owns that value disconnects, the other device will stop using that value, which could trigger a bundle flap.
Correct the misconfiguration to clear the alarm by configuring the same value for those configuration items on each router in the RG.
MLACP_BUNDLE_MAC_ARBITRATION: The MAC address for <bundle name> has been selected through arbitration.
This is the same as the system ID arbitration alarm but for the mac-address configuration under the bundle interface. This should also be the same for a bundle on all devices operating that bundle.
MLACP_UNRESOLVABLE_MISCONFIG_DISCONNECT: Disconnecting from <LDP ID> due to an unresolvable misconfiguration: <reason> MLACP_RESYNC_INCONSISTENCY_DISCONNECT: Disconnecting from <LDP ID due to an inconsistency in the mLACP data that could not be resolved with a resynchronization. Reason: <reason>
The configuration specified is mismatched between the two POAs.
To recover from this situation you must correct the configuration mismatch, and then remove and re-add an item of RG mLACP configuration (e.g. the mlacp node under the ICCP group submode) on both POAs.
MLACP_DEVICE_MISCONFIGURATION: <reason>
Correct the specified misconfiguration to clear this issue.
MLACP_ITEM_MISCONFIGURATION: <details>
This message indicates a possible issue, but can be safely ignored. If there is an ongoing issue, an MLACP_DEVICE_MISCONFIGURATION message will be emitted shortly afterwards.
MLACP_ROID_MISMATCH: The ROID (<value>) received from <LDP ID> for <bundle name>, does not match that expected (<value). Please ensure that the ROID for the bundle is the same on both devices.
In 4.0, the ROID of the bundle is generated in a set format from the bundle ID, in both the XR and IOS implementations. However, in future it is possible that the ROID will be configurable. So the current implementation emits this message if it gets an unexpected value for the ROID.
MLACP_CORE_ISOLATION: <bundle name> marked as isolated due to not being able to connect to the core.
ICCP has declared a core isolation event for the redundancy group. As a result, the bundle infra has declared this bundle as isolated, and will switch over to the standby POA if it is available.
MLACP_BUNDLE_PEERING: <bundle name> is peering with <LDP ID> MLACP_BUNDLE_PEERING: <bundle name> is no longer peering with <LDP ID>
This message indicates that the peer device being used for operating mLACP on this bundle (or that there is no longer an mLACP peer for this bundle).
MLACP_BUNDLE_ACTIVE: This device is now the active device for <bundle> MLACP_BUNDLE_ACTIVE: This device is no longer the active device for <bundle>
This message indicates that the local device has taken on the Active role for the bundle in question, or has surrendered that role to the peer. This may be an expected event or may indicate that some fault has occured to trigger a switchover. Investigate as appropriate.
Recovering from failures
If you've identified a problem and collected all the necessary information, or you've hit a known issue, there are some common steps you might be able to use to recover the testbed without needing to reload:
- Shut/no shut the bundle or member that's causing a problem.
- Unconfigure/reconfigure the bundle or member.
process restart bundlemgr_distrib
process restart mpls_ldp
Remove then add some mLACP configuration under the ICCP group on both POAs, e.g. the mlacp nodde (to cause a reconnection to the ICCP group by mLACP).
23.
Simple quick config blocks
The connections in this topology are as follows:
DHD POA 1 POA 2 Gi0/0/0/0 --------------- Gi0/0/0/0 Gi0/0/0/1 --------------- Gi0/0/0/1 Gi0/0/0/2 Gi0/0/0/3 ----------------------------------------- Gi0/0/0/0 Gi0/0/0/4 ----------------------------------------- Gi0/0/0/1 Gi0/0/0/2 Gi0/0/0/2 Gi0/0/0/3 --------------- Gi0/0/0/3 Gi0/0/0/4 --------------- Gi0/0/0/4
| POA 1 |
|---|
redundancy iccp group 1 mlacp node 1 mlacp system mac 000d.000e.000f mlacp system priority 1 member neighbor 5.4.3.2 ! ! ! ! interface Bundle-Ether1 lacp switchover suppress-flaps 300 mlacp iccp-group 1 mac-address 0.deaf.0 bundle wait-while 100 ! interface Loopback0 ipv4 address 5.4.3.1 255.255.255.255 ! interface GigabitEthernet0/0/0/0 description Connected to DHD Gi0/0/0/0 bundle id 1 mode active lacp period short no shutdown ! interface GigabitEthernet0/0/0/3 description Connected to POA2 Gi0/0/0/3 ipv4 address 1.2.3.1 255.255.255.0 proxy-arp no shutdown ! router static address-family ipv4 unicast 5.4.3.2/32 1.2.3.2 ! ! mpls ldp router-id 5.4.3.1 discovery targeted-hello accept log neighbor ! interface GigabitEthernet0/0/0/3 ! ! |
| POA 2 |
|---|
redundancy iccp group 1 mlacp node 2 mlacp system mac 000d.000e.000f mlacp system priority 1 member neighbor 5.4.3.1 ! ! ! ! interface Bundle-Ether1 lacp switchover suppress-flaps 300 mlacp iccp-group 1 mac-address 0.deaf.0 bundle wait-while 100 ! interface Loopback0 ipv4 address 5.4.3.2 255.255.255.255 ! interface GigabitEthernet0/0/0/0 description Connected to DHD Gi0/0/0/3 bundle id 1 mode active lacp period short no shutdown ! interface GigabitEthernet0/0/0/3 description Connected to POA1 Gi0/0/0/3 ipv4 address 1.2.3.2 255.255.255.0 proxy-arp no shutdown ! router static address-family ipv4 unicast 5.4.3.1/32 1.2.3.1 ! ! mpls ldp router-id 5.4.3.2 discovery targeted-hello accept log neighbor ! interface GigabitEthernet0/0/0/3 ! ! |
| On the DHD |
|---|
interface Bundle-Ether1 lacp switchover suppress-flaps 300 bundle wait-while 100 ! interface GigabitEthernet0/0/0/0 description Connected to POA1 Gi0/0/0/0 bundle id 1 mode active lacp period short no shutdown ! interface GigabitEthernet0/0/0/3 description Connected to POA2 Gi0/0/0/0 bundle id 1 mode active lacp period short no shutdown ! |
Related Information
Xander Thuijs, CCIE #6775
- Principal Engineer ASR9000
No comments:
Post a Comment